nf-core/rnafusion
RNA-seq analysis pipeline for detection of gene-fusions
3.0.1). The latest
stable release is
3.0.2
.
Introduction
nf-core/rnafusion is a bioinformatics best-practice analysis pipeline for RNA sequencing consisting of several tools designed for detecting and visualizing fusion genes. Results from up to 5 fusion callers tools are created, and are also aggregated, most notably in a pdf visualiation document, a vcf data collection file, and html and tsv reports.
On release, automated continuous integration tests run the pipeline on a full-sized dataset on the AWS cloud infrastructure. This ensures that the pipeline runs on AWS, has sensible resource allocation defaults set to run on real-world datasets, and permits the persistent storage of results to benchmark between pipeline releases and other analysis sources. The results obtained from the full-sized test can be viewed on the nf-core website.
In rnafusion the full-sized test includes reference building and fusion detection. The test dataset is taken from here.
Pipeline summary
Build references
--build_references triggers a parallel workflow to build references, which is a prerequisite to running the pipeline:
- Download ensembl fasta and gtf files
- Create STAR index
- Download Arriba references
- Download FusionCatcher references
- Download and build STAR-Fusion references
- Download Fusion-report DBs
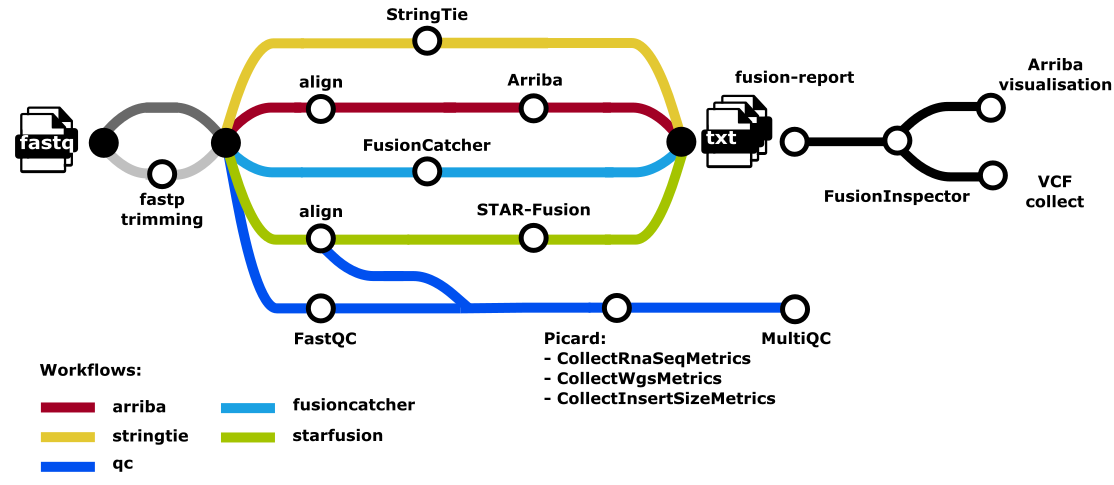
Main workflow
- Input samplesheet check
- Concatenate fastq files per sample (cat)
- Reads quality control (FastQC)
- Optional trimming with fastp
- Arriba subworkflow
- STAR-fusion subworkflow
- STAR alignment
- STAR-Fusion fusion detection
- Fusioncatcher subworkflow
- FusionCatcher fusion detection
- StringTie subworkflow
- Fusion-report
- Merge all fusions detected by the selected tools with Fusion-report
- Post-processing and analysis of data
- FusionInspector
- Arriba visualisation
- Collect metrics (
picard CollectRnaSeqMetrics,picard CollectInsertSizeMetricsand (picard MarkDuplicates)
- Present QC for raw reads (
MultiQC) - Compress bam files to cram with samtools view
Usage
If you are new to Nextflow and nf-core, please refer to this page on how
to set-up Nextflow. Make sure to test your setup
with -profile test before running the workflow on actual data.
As the reference building is computationally heavy (> 24h on HPC), it is recommended to test the pipeline with the -stub parameter (creation of empty files):
First, build the references:
nextflow run nf-core/rnafusion \
-profile <docker/singularity/.../institute> \
-profile test \
--outdir <OUTDIR>\
--build_references \
-stubThen perform the analysis:
nextflow run nf-core/rnafusion \
-profile <docker/singularity/.../institute> \
-profile test \
--outdir <OUTDIR>\
-stubPlease provide pipeline parameters via the CLI or Nextflow -params-file option. Custom config files including those
provided by the -c Nextflow option can be used to provide any configuration except for parameters;
see docs.
Notes:
- Conda is not currently supported; run with singularity or docker.
- Paths need to be absolute.
- GRCh38 is the only supported reference.
- Single-end reads are to be used as last-resort. Paired-end reads are recommended. FusionCatcher cannot be used with single-end reads shorter than 130 bp.
For more details and further functionality, please refer to the usage documentation and the parameter documentation.
Pipeline output
To see the results of an example test run with a full size dataset refer to the results tab on the nf-core website pipeline page. For more details about the output files and reports, please refer to the output documentation.
Credits
nf-core/rnafusion was written by Martin Proks (@matq007), Maxime Garcia (@maxulysse) and Annick Renevey (@rannick)
We thank the following people for their help in the development of this pipeline:
Contributions and Support
If you would like to contribute to this pipeline, please see the contributing guidelines.
For further information or help, don’t hesitate to get in touch on the Slack #rnafusion channel (you can join with this invite).
Citations
If you use nf-core/rnafusion for your analysis, please cite it using the following doi: 10.5281/zenodo.3946477
An extensive list of references for the tools used by the pipeline can be found in the CITATIONS.md file.
You can cite the nf-core publication as follows:
The nf-core framework for community-curated bioinformatics pipelines.
Philip Ewels, Alexander Peltzer, Sven Fillinger, Harshil Patel, Johannes Alneberg, Andreas Wilm, Maxime Ulysse Garcia, Paolo Di Tommaso & Sven Nahnsen.
Nat Biotechnol. 2020 Feb 13. doi: 10.1038/s41587-020-0439-x.
run with
subscribers
stars
open issues
open PRs
last release
last update
contributors
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")